The series so far:
- Heaps in SQL Server: Part 1 The Basics
- Heaps in SQL Server: Part 2 Optimizing Reads
- Heaps in SQL Server: Part 3 Nonclustered Indexes
After looking at the internal structures and the selection of data in heaps in the previous articles, the next articles will describe how DML operations can be optimized on a heap.
Demo set up
I use data from a demo database for all demos for demonstration purposes in articles and conferences. You can download the database [CustomerOrders] here.
In this article, I’ll use an additional database, demo_db. Run the following script to create the demo_db database, a heap to test inserts, and a view pointing to [CustomerOrders].
CREATE DATABASE demo_db;
GO
USE demo_db;
GO
CREATE TABLE dbo.Customers
(
Id INT NOT NULL,
Name VARCHAR(200) NOT NULL,
CCode CHAR(3) NOT NULL,
State VARCHAR(200) NOT NULL,
ZIP CHAR(10) NOT NULL,
City VARCHAR(200) NOT NULL,
Street VARCHAR(200) NOT NULL
);
GO
CREATE VIEW dbo.CustomerAddresses
AS
SELECT C.Id,
C.Name,
A.CCode,
A.State,
A.ZIP,
A.City,
A.Street
FROM CustomerOrders.dbo.Customers AS C
INNER JOIN CustomerOrders.dbo.CustomerAddresses AS CA
ON (C.Id = CA.Customer_Id)
INNER JOIN CustomerOrders.dbo.Addresses AS A
ON (CA.Address_Id = A.Id)
WHERE CA.IsDefault = 1;
GO
Standard Procedure – INSERT
When data records are entered in a heap, this process consists of several individual steps that are transparent to the applications. Knowing them leaves room for possible optimization of the process.
Update of PFS
If a data row is stored in a heap and there is not enough space available on the data page, a new data page must be created. The data record can only be saved after the new page has been created.
In the first demo, insert one row into the formerly created table from the created view.
CHECKPOINT; GO INSERT INTO dbo.Customers SELECT * FROM dbo.CustomerAddresses WHERE Id = 1; GO
The above example adds a new record from an existing data source to the new table. Since the table was previously empty, the table structure must first be created. The undocumented function sys.fn_dblog () can be used to determine which tasks Microsoft SQL Server had to perform to insert the record into the table. I used CHECKPOINT to eliminate previous operations from appearing in the results below.
SELECT ROW_NUMBER() OVER (ORDER BY [Current LSN]) [Step #],
[Current LSN],
Operation,
Context,
AllocUnitName,
[Page ID],
[Slot ID]
FROM sys.fn_dblog(NULL, NULL)
WHERE CONTEXT <> N'LCX_NULL'
AND AllocUnitName IS NOT NULL;
GO
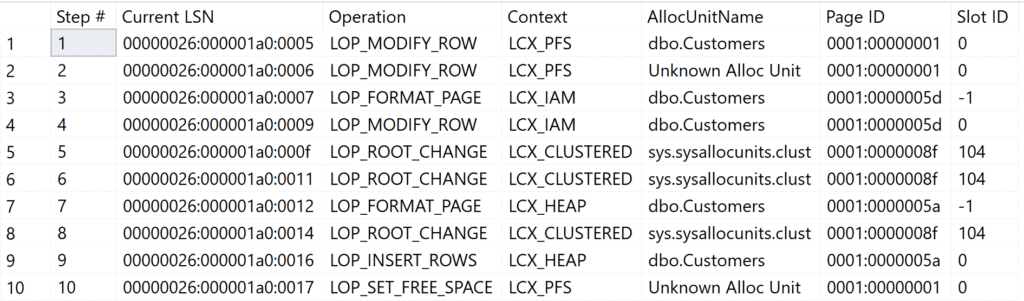
Figure 1: Recording from the Transaction Log
|
Step(s) |
Operation and Context |
Description |
|---|---|---|
|
1 and 2 |
LOP_MODIFY_ROW / LCK_PFS |
Since data pages are first created for the table, each assignment must be “registered” in the PFS page. A data page and the IAM page are created and registered for the table. |
|
3 |
LOP_FORMAT_PAGE / LCX_IAM |
Creation of the IAM page for table dbo.Customers |
|
4 |
LOP_MODIFY_ROW / LCX_IAM |
Registration of the first data page in IAM page |
|
5 and 6 |
LOP_ROOT_CHANGE / LCX_CLUSTERED |
Registration of table metadata in Microsoft SQL Server system tables |
|
7 |
LOP_FORMAT_PAGE / LCX_HEAP |
Preparation of the data page for the heap for storing the records. |
|
8 |
LOP_ROOT_CHANGE / LCX_CLUSTERED |
Storage of metadata in Microsoft SQL Server system tables |
|
9 |
LOP_INSERT_ROWS / LCX_HEAP |
Insert row in Heap |
|
10 |
LOP_SET_FREE_SPACE / LCX_PFS |
Update of the filling level of the data page for the PFS page |
Note: I describe the system pages and their functions in detail in the article “Heaps – The Basics”.
If further records are entered, the existing data page is filled until it is – in percentage terms – so full that no new records can be saved on it and Microsoft SQL Server has to allocate the next data page in the system.
Run this script to add another 10,000 rows.
CHECKPOINT;
GO
DECLARE @I INT = 2
WHILE @I <= 10000
BEGIN
INSERT INTO dbo.Customers
SELECT * FROM dbo.CustomerAddresses
WHERE Id = @I;
SET @I += 1;
END
GO
Another 10,000 records will be inserted into the table [dbo].[Customers] with the code above. Afterwards, look into the Transaction log to see the single transactional steps.
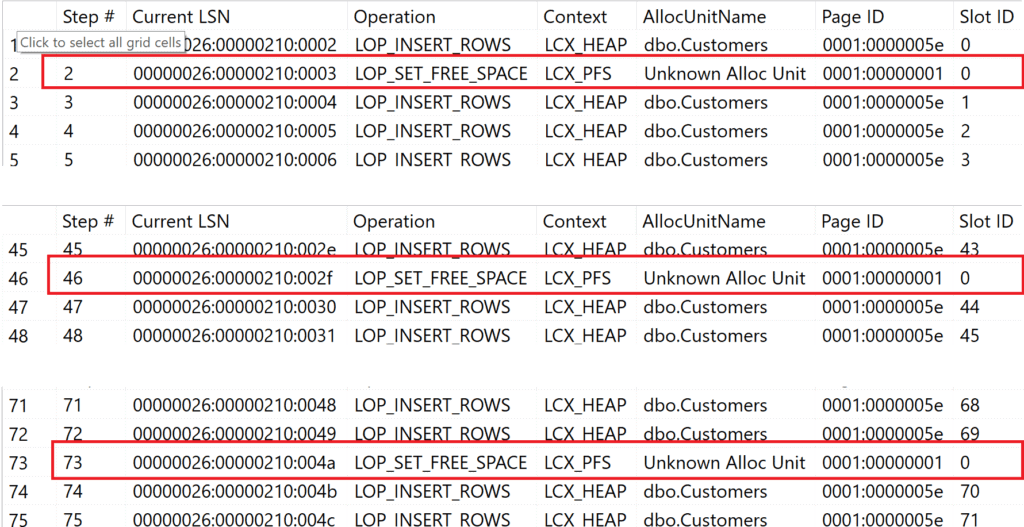
Figure 2: PFS updates
You can see that Microsoft SQL Server must update the PFS page several times (line 2, 46, 73, …). This is because the PFS page – only in the case of heaps – needs to be updated every time the next threshold is reached.
Bottleneck PFS
The PFS page “can” become a bottleneck for a heap if many data records are entered in the heap in the shortest possible time. How often the PFS page has to be updated depends mostly on the data record’s size to be saved.
This procedure does not apply to clustered indexes since data records in an index must ALWAYS be “sorted” into the data volume according to the defined index value. Therefore, the search for a “free” space is not carried out via the PFS page but via the value of the key attribute!
Microsoft SQL Server must explicitly check after each insert process whether the PFS page needs to be updated or not. If the above result is reduced to processes on the PFS page, the process is easy to recognize.
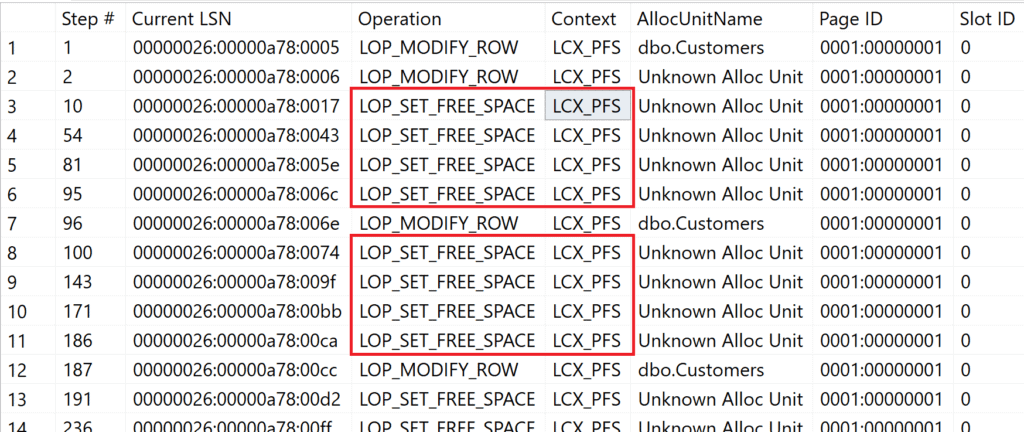
Figure 3: Filtered operations from the log for PFS activity
In total – due to the short data record length – the PFS page had to be updated 14 times in order to enter 10,000 data records in the heap.
At first glance, that may not seem like a lot – after all, 10,000 records were entered. However, it can become problematic for the PFS page as soon as more than one process wants to enter data in the table at the same time. To derive – imprecise due to the limitations of my test system! – a trend, I had the latches recorded on the PFS page with the help of an extended event session and then processed the above (wrapped in a stored proc) in parallel with a different number of clients.
CREATE OR ALTER PROC dbo.InsertCustomerData
@NumOfRecords INT
AS
BEGIN
WHILE @NumOfRecords > 0
BEGIN
INSERT INTO dbo.Customers
SELECT * FROM dbo.CustomerAddresses
WHERE Id = @NumOfRecords;
SET @NumOfRecords -= 1;
END
END
GO
CREATE EVENT SESSION [track pfs contention]
ON SERVER
ADD EVENT sqlserver.latch_suspend_end
(
ACTION(package0.event_sequence)
WHERE
(
sqlserver.database_name = N'demo_db'
AND sqlserver.is_system = 0
AND mode >= 0
AND mode <= 5
)
AND class = 28
AND
(
-- only check for PFS, GAM, SGAM
page_id = 1
OR page_id = 2
OR page_id = 3
OR package0.divides_by_uint64(page_id, 8088)
OR package0.divides_by_uint64(page_id, 511232)
)
)
ADD TARGET package0.event_file
(
SET filename = N'T:\TraceFiles\PFS_Contention.xel',
MAX_FILE_SIZE = 1024,
MAX_ROLLOVER_FILES = 10
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 5 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = OFF,
STARTUP_STATE = OFF
)
GO
I carried out each series of tests five times to compensate for possible deviations. After each workload, the recordings from the extended event has been analysed with the following query:
SELECT CAST(event_Data AS xml) AS StatementData
INTO #EventData
FROM sys.fn_xe_file_target_read_file
('T:\TraceFiles\PFS*.xel', NULL, NULL, NULL);
GO
SELECT * FROM #EventData;
GO
WITH XE
AS
(
SELECT StatementData.value('(event/@timestamp)[1]','datetime') AS [time],
StatementData.value('(event/@name)[1]', 'VARCHAR(128)') AS [Event_name],
StatementData.value('(event/data[@name="mode"]/text)[1]','VARCHAR(10)') AS [mode],
StatementData.value('(event/data[@name="duration"]/value)[1]','int') AS [duration],
StatementData.value('(event/data[@name="page_type_id"]/text)[1]','VARCHAR(64)') AS [page_type]
FROM #EventData
)
SELECT XE.page_type,
COUNT_BIG(*) AS num_records,
SUM(XE.duration) AS sum_duration,
AVG(XE.duration) AS avg_duration
FROM XE
GROUP BY
XE.page_type
GO
|
Processes |
1 |
2 |
4 |
8 |
16 |
32 |
64 |
|
PFS-Contention |
0 |
1 |
1 |
7 |
7 |
16 |
68 |
|
avg. duration (µsec) |
0 |
0 |
27 |
305 |
790 |
1.113 |
3.446 |
|
Runtime (sec) |
4,28 |
5,65 |
7,68 |
13,45 |
23,83 |
55,93 |
165,72 |
|
avg (µsec)/ row |
428 |
2.825 |
192 |
16.813 |
16.769 |
17.478 |
25.894 |
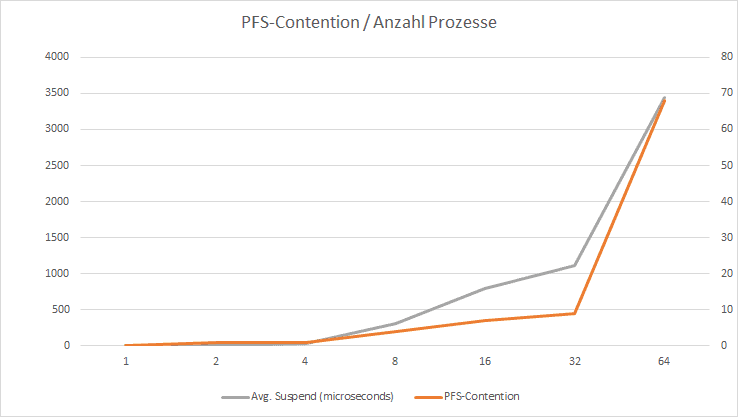
Figure 4: Dependence on processes to contention(s)
The tests I carried out are not representative because external influences were not properly isolated. Nevertheless, one can deduce from the values that the potential for contention on the PFS page escalates with an increasing number of simultaneous processes.
You know the problem from everyday life; You have to queue longer the more people want to use the same resource (till in the supermarket) at the same time. The bottleneck can be rectified by working with multiple files for the filegroup in which the heap is located – as is also common practice with TEMPDB.

Figure 5: A separate database file for each core
I performed the same workload with 4 database files for the PRIMARY filegroup, and the results have been observed with the Windows Resource Manager:

Figure 6: Relatively even distribution of the write load – better throughput
BTW: Now it is a good time to learn “a few” german words like
Datei = File
Lesen = read
Schreiben = write
It was to be expected that this would ease the situation. You can think of it as a situation in a supermarket where only one till is open at first. As soon as there are many customers in the supermarket, it accumulates in front of the till. Several cash registers are opened, and the situation is more relaxed again.
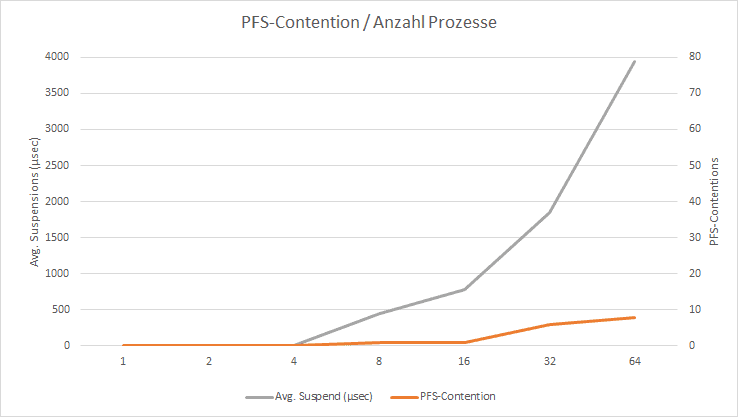
Figure 7: Significant relaxation for the PFS pages
Bottleneck data structure
Anyone working with heaps must take the data structures into account. The biggest difference in the storage of data between an index and a heap is that data in a heap can be stored anywhere, while indexed tables must store the data according to the index attribute’s value. Storing data in a Heap can result in several problems:
Waste of storage space due to the calculation of the percentage of available storage space on a data page
Waste of memory in the buffer pool, since it is not the data itself that is loaded into the buffer pool, but the data pages on which the data is located
Increased contention on the PFS page if data records are too large and the percentage filling level has to be updated quickly.
Unused memory on a data page
Memory is expensive and, for Microsoft SQL Server, it’s an important component for fast queries. For this reason, you naturally want to avoid the situation where data pages are not completely filled, and thus RAM cannot be used.
To demonstrate this huge discrepancy between a Heap and a Clustered Index, create in the first scenario, a Heap table with a column C2 with a fixed size of 2,000 bytes for the payload. Afterwards, a Stored Procedure inserts 10,000 rows into the Heap table.
USE demo_db;
GO
DROP TABLE IF EXISTS dbo.Customers;
GO
-- Create a demo table
CREATE TABLE dbo.Customers
(
C1 INT NOT NULL IDENTITY (1, 1),
C2 CHAR(2000) NOT NULL DEFAULT ('Testdata'),
);
GO
-- Create stored procedure for the INSERT process
CREATE OR ALTER PROC dbo.InsertCustomerData
@NumOfRecords INT
AS
BEGIN
WHILE @NumOfRecords > 0
BEGIN
INSERT INTO dbo.Customers
(C2)
DEFAULT VALUES;
SET @NumOfRecords -= 1;
END
END
GO
-- Execution of stored procedures for 10,000 rows
EXEC dbo.InsertCustomerData @NumOfRecords = 10000;
GO
The example above creates the table [dbo].[Customers] and a simple Stored Procedure which gets the number of rows to be inserted from a variable. After the insert process, you can get insights into the data distribution with the next query, which retrieves the physical information about the stored data.
SELECT page_count,
record_count,
record_count / page_count AS avg_rows_per_page,
avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Customers', N'U'),
NULL,
NULL,
N'DETAILED'
)
WHERE index_level = 0;
GO

With the table’s current design, two or three records (avg) can be stored on one data page. This means that a data page is filled with approx. 50 – 75%. If you change the Heap Table to a Clustered Index Table, the results look completely different!
DROP TABLE IF EXISTS dbo.Customers;
GO
-- Create a demo table
CREATE TABLE dbo.Customers
(
C1 INT NOT NULL IDENTITY (1, 1),
C2 CHAR(2000) NOT NULL DEFAULT ('Testdata'),
CONSTRAINT pk_Customers_C1 PRIMARY KEY CLUSTERED (C1)
);
GO
-- Execution of stored procedures for 10,000 rows
EXEC dbo.InsertCustomerData @NumOfRecords = 10000;
GO

The reason for this odd behaviour is that Microsoft SQL Server references ONLY to the PFS page when it comes to the storage of a record in a Heap while a Clustered Index always has to follow the restriction of the Clustered Key and stores the record on the position of the key in the table.
A clustered index outperforms – based on the storage consumption – the Heap due to the need to store a record based on the key attribute. But keep in mind that – different from a Heap structure – the INSERT process requires to follow the B-Tree structure when it must safe a record on a data page.
Note
Before you go for a Heap structure, perform some tests to understand your data distribution in the data pages!
Workload when inserting records
The following demonstration shows the dependencies between the row size and the remaining free space on a data page.
IF OBJECT_ID(N'dbo.demo_table', N'U') IS NOT NULL
DROP TABLE dbo.demo_table;
GO
-- The size of the column C1 will change with every test!
CREATE TABLE dbo.demo_table (C1 CHAR(100) NOT NULL);
GO
-- Clear the log file for the analysis of PFS updates
CHECKPOINT;
GO
-- This script will run for each test loop and insert
-- 10,000 records into the table
BEGIN TRANSACTION InsertRecord;
GO
DECLARE @I INT = 1;
WHILE @I <= 10000
BEGIN
INSERT INTO dbo.demo_table(C1) VALUES ('This is a test');
SET @I += 1;
END
-- Afterwards we count the log entries for the PFS updates
SELECT Context,
COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL)
WHERE [Transaction ID] IN
(
SELECT [Transaction ID]
FROM sys.fn_dblog(NULL, NULL)
WHERE [Transaction Name] = N'InsertRecord'
OR Context = N'LCX_PFS'
)
GROUP BY
Context;
-- and have a look to the avg space used in the heap
SELECT page_count,
avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.demo_table', N'U'),
0,
NULL,
N'DETAILED'
);
GO
ROLLBACK TRANSACTION;
GO
The above demonstration has been run with different row sizes. The result of the tests with different row sizes gave the following results:
While the duration of the transaction runtime changes moderately (157 ms – 1.459 ms), the number of updates of the PFS page increases extremely beginning with a record length of 200 bytes (563 – 16.260). Although the PFS page refresh occurs quite frequently, the number of data pages grows moderately (149-5,000). The average filling level of a data page is between 75% and 100%, depending on the size of the row.
The PFS page’s frequent updating is explained by the growing size of a data record since fewer data records fit on one data page and the various thresholds can be reached more quickly.
|
Record Length |
Time (ms) |
PFS Update |
Pages |
Avg. Used space |
|
100 |
157 |
563 |
149 |
90,36% |
|
200 |
414 |
1,397 |
271 |
95,26% |
|
500 |
441 |
3,199 |
777 |
80,91% |
|
1000 |
595 |
5,916 |
1,436 |
86,79% |
|
2000 |
920 |
10,625 |
3,339 |
74,31% |
|
3000 |
1,138 |
16,069 |
5,004 |
74,27% |
|
4000 |
1,459 |
16,260 |
5,000 |
99,04% |
Let’s do a little maths when data are stored on a data page.
|
Bytes |
50% |
80% |
95% |
100% |
|---|---|---|---|---|
|
100 |
40 |
64 |
76 |
80 |
|
200 |
20 |
32 |
38 |
40 |
|
500 |
8 |
12 |
15 |
16 |
|
1000 |
4 |
6 |
7 |
8 |
|
2000 |
2 |
3 |
3 |
4 |
|
3000 |
1 |
2 |
2 |
2 |
|
4000 |
1 |
2 |
The above table shows the maximum records which “should” fit on ONE data page when the threshold has exceeded. Please note that with a fill level of 95%, only 403 bytes (8.060 * (1-95%)) are mathematically available on the data page.
If the row size is 100 Bytes, Microsoft SQL Server can store 40 records on ONE data page before the threshold gets updated to 80%. It takes 24 more records before the next update to 95% will happen.
As bigger the row size is as faster will the thresholds be reached. Keep in mind that the row size has an direct impact on the possible contention on the PFS page.
Let’s take a row size of 1,000 bytes for a record. With the 5th record, the PFS gets updated to 80%. When the 6th row (1,000 Bytes) must be stored on a data page, it will fit perfectly. From the table above, you can see the green and red values.
The green values mean that the records can be stored on the data page while the red ones show the records which will request a new data page!
Summary
The aim when inserting new data in a heap is to avoid frequent updates of the PFS pages and to use the available space as max as possible. The next article will show how you can boost the performance when you insert data into a Heap.
The post Heaps in SQL Server: Part 4 PFS contention appeared first on Simple Talk.
from Simple Talk https://ift.tt/3niL8LM
via
No comments:
Post a Comment