Kubeflow is a Machine Learning platform that runs on top of Kubernetes and provides end to end functionality for executing machine learning projects. Google created it for internal use of running Tensorflow jobs on Kubernetes, and they later released it as open-source in 2018. Kubeflow has become an essential toolkit for data scientists today since it abstracts them from the underlying complexities of Kubernetes and provides a seamless platform for easy execution and faster delivery of machine learning projects. To appreciate how Kubeflow can make a remarkable difference in a machine learning project, you first need to understand the pain points of data scientists.

Why is Kubeflow important for data scientists?
Around four to five years back when the hype of machine learning and data science had just started, everyone tried to capitalize on the trend in a rush. Individuals spent a considerable amount of time and effort to learn machine learning. In contrast, companies pumped millions of dollars overnight to launch their ML and DS projects. Yet, according to a Dec 2019 report, only 22% of companies running machine learning projects could deploy a model to production at all. And more than 43% of the respondents admitted they struggle to scale the ML projects according to the company’s needs.
The main reason behind this high failure rate is that everyone focused only on learning ML and DS concepts with POC work on their local Jupyter notebooks in the initial days. There was no thought process on how to practically execute real-world ML projects and deliver them to production successfully. This lack of understanding became visible when these projects started to fail in companies.

Since the ML project life cycle differs from the traditional software life cycle, the concept of MLOPs was soon introduced as a framework similar to DevOps to speed up the delivery of ML projects. To bring consistency and ease in the scalable model deployment process, containerization technologies like Docker and Kubernetes were also introduced for ML projects. Kubernetes is an orchestration framework for containers, specifically allowing easier deployment, horizontal scaling, and load balancing for the ML models.
However, as another report suggests, 39% of the data scientists still find it difficult to work with Docker and Kubernetes. This skill gap becomes a challenge for deploying ML models successfully to production. Even though Docker and Kubernetes can make life easy, they are separate technologies and require different expertise than machine learning to make the best use of them.
There was a growing realization that the data scientists should not be exposed to the complexities of managing the infrastructure side of the ML projects and should be given an abstracted platform where they can focus on what they can do best, crunch data, and create ML models. This is where the release of Kubeflow by Google became a game-changer for data scientists, and you’ll see how in the next section.
Features of Kubeflow
As mentioned in the beginning, Kubeflow is an end-to-end platform for creating, training, and deploying ML models and can run on any place where Kubernetes is already present. Kubeflow is now available on Google Cloud Platform, AWS, and Azure as services but you can also install Kubeflow on-premises or your local laptop. Let us now do a deep dive into Kubeflow offerings.
Model building and training
Kubeflow provides managed Jupyter Notebook instances that can be used for experimenting and creating prototypes of the ML models. It supports the popular libraries of Scikit Learn, Tensorflow, PyTorch, XGBoost and you can also carry out distributed training with the help of TF Jobs.
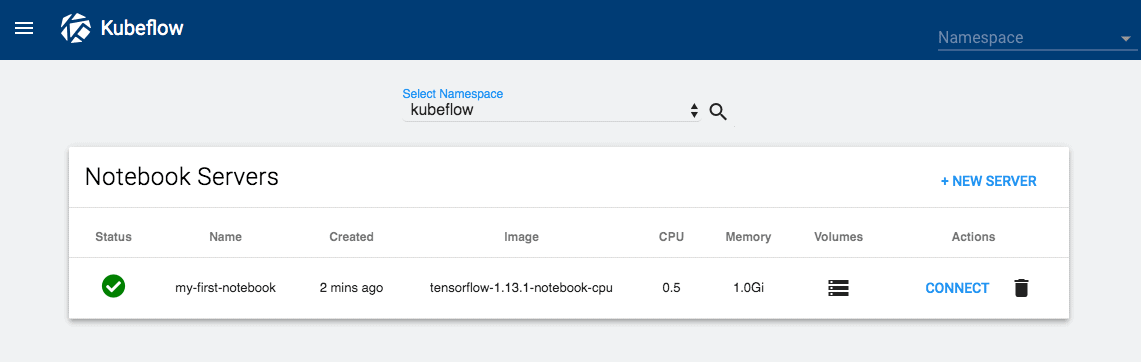
Jupyter Notebook on KubeFlow (Source)
Hyperparameter tuning
Finding the right set of hyperparameters for your model is not an easy manual task as it can be very time-consuming and may not even guarantee an optimal set of hyperparameters.
Katib is Kubeflow’s Hyperparameter tuning system that runs on Kubernetes underneath it to automatically optimize hyperparameters for the best results in less time.
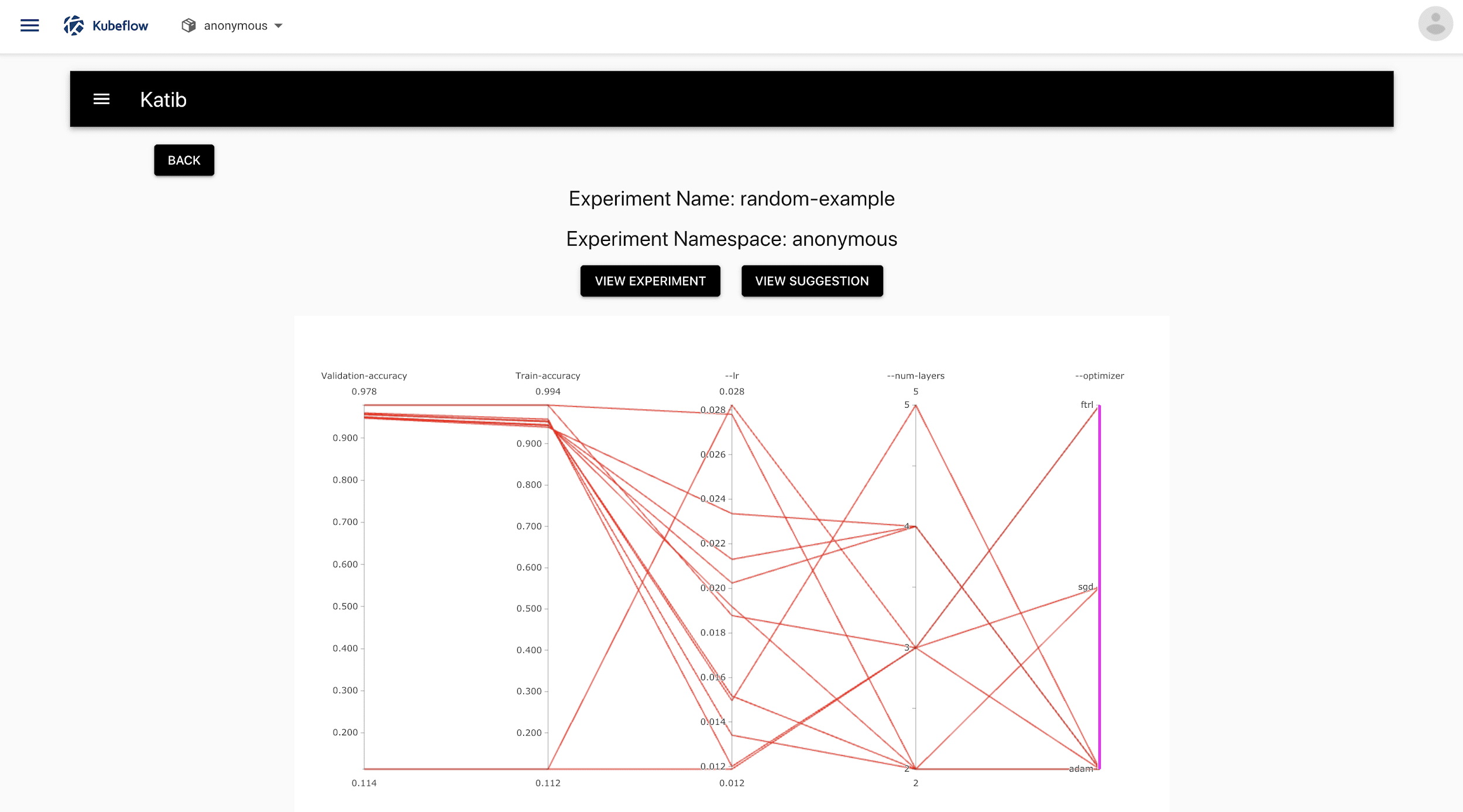
Hyperparameter Tuning using Kubeflow Katib (Source)
Model deployment and serving
As shown above, deployment and serving of ML models in production in a scalable manner is the most challenging task for data scientists, but Kubeflow has made this task very easy with plenty of serving tools available for your needs
First of all, it provides KFServing which is a model serving tool that supports multiple frameworks like Tensorflow, PyTorch, Scikit Learn, XGBoost, ONNX. Under the hood, KFServing sets up serverless inference on Kubernetes by hiding the underlying complexity from the user. It takes care of autoscaling and health check of the underlying Kubernetes cluster on its own.
Besides, KFServing, there is another option of Seldon Core and BentoML which are other multi-framework supported serving tools. And in case you are working on the TensorFlow model you can also use the TensorFlow Serving that is available on Kubeflow.
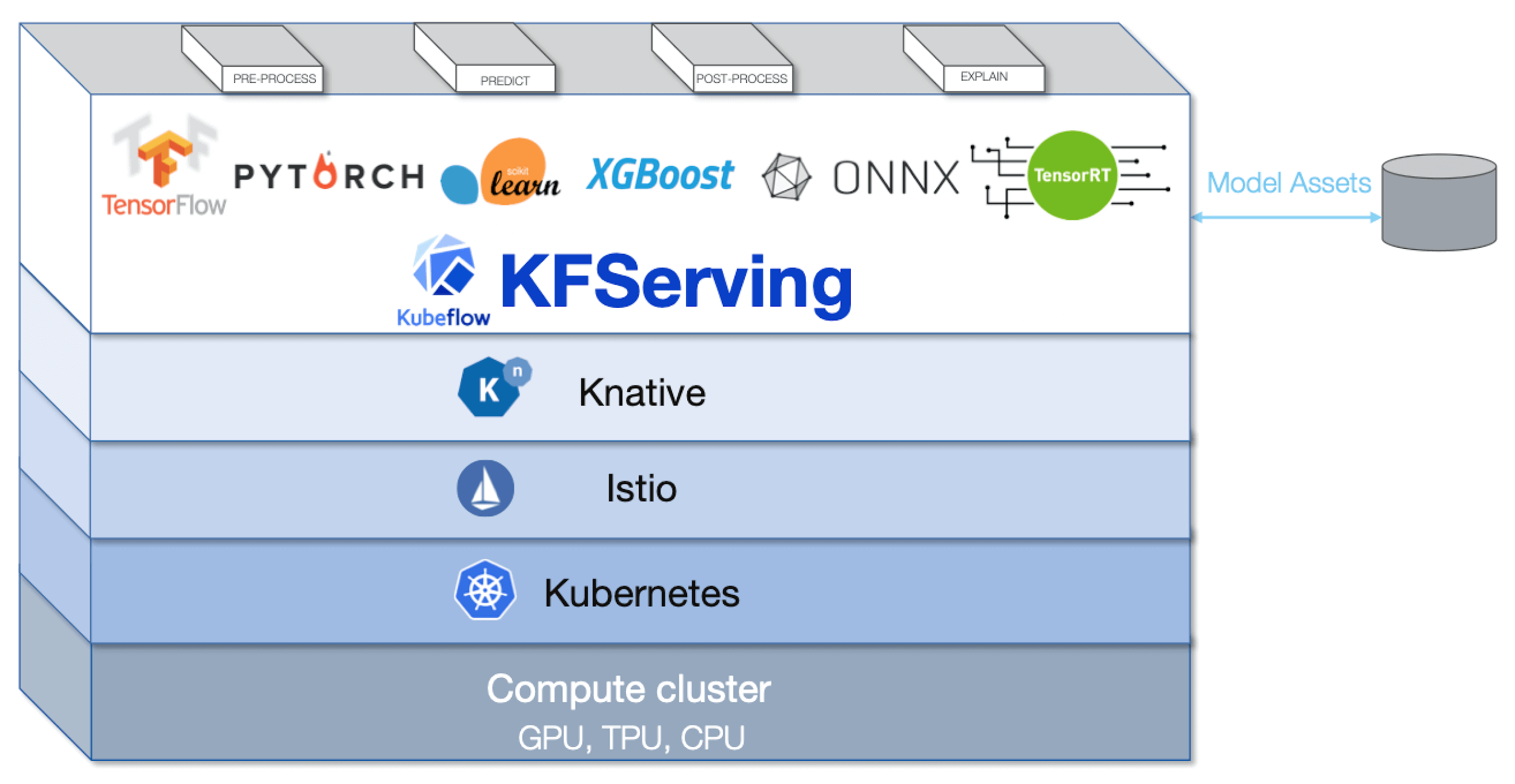
KFServing (Source)
Portability and flexibility
Even though Kubeflow has various components to cater to different phases of an ML project life cycle, it does not restrict you to use it only for end-to-end purposes. It gives the flexibility to choose one or more components as per your needs, and, to support this flexibility, it also ensures portability across multiple infrastructures and clouds. This enables you to build and train the model externally and then use KubeFlow only for model deployment purposes. Or you may create and train the model on KubeFlow and then deploy it on some cloud for serving.

Kubeflow provides portability across clouds and other infrastructure (Source)
KubeFlow pipelines for CI/CD
The concept of machine learning pipelines for MLOPs actually comes from the DevOPs pipeline to ensure continuous integration and continuous deployment. Kubeflow CI/CD pipelines not only ensure automation of the ML workflows for faster delivery of changes but are also useful to create workflows that are reproducible for scalability.
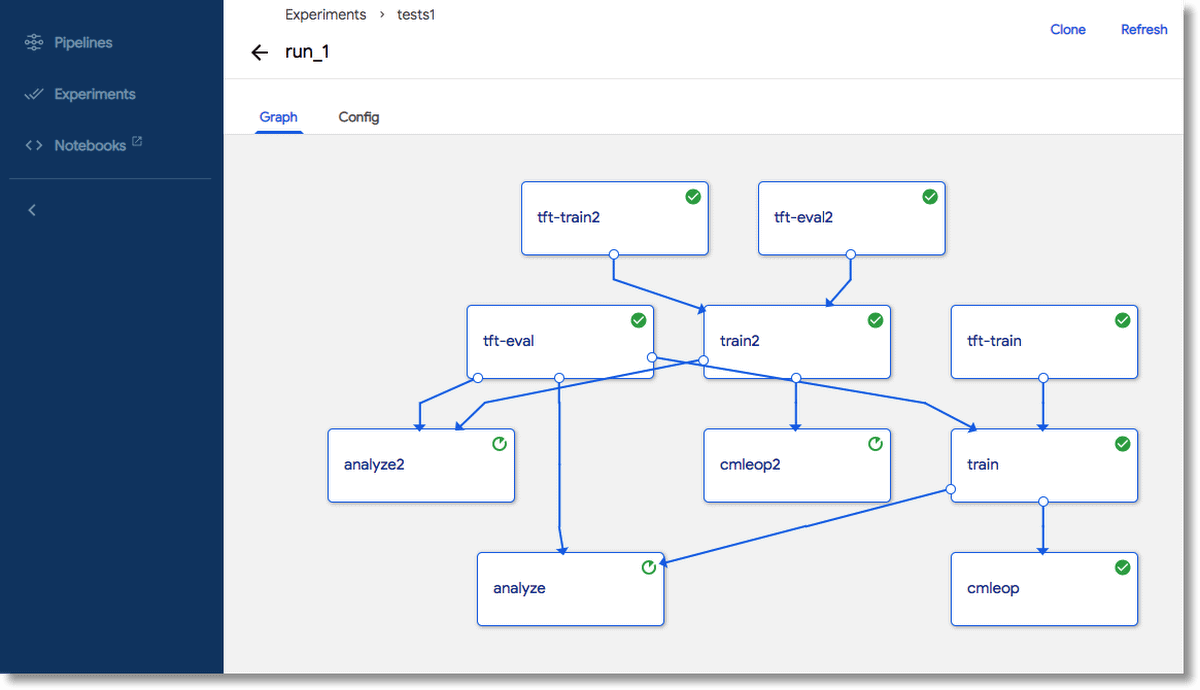
Kubeflow Pipeline (Source)
Kubeflow Fairing
Kubeflow provides a high-level Python SDK – Fairing for creating, training, and deploying machine learning models locally and more importantly, remotely on Cloud. Fairing abstracts the users from the complexity of working with Cloud by streamlining the training and deployment process with just a few lines of codes so that you can focus only on ML models as data scientists.
As per the current documentation, Fairing supports working with GCP, AWS, Azure, and IBM Cloud.
Example – Kubeflow Fairing with AWS
The example below deals with the House Pricing Prediction problem and shows model creation, training, deployment, and serving using Fairing.
- ML Code – This snippet shows the code for training and prediction written inside the HousingServe class. (Additional details are omitted from here to keep the focus on the Fairing part, original code can be found here )

- AWS Setup – The next section shows how to set up Kubeflow Fairing with an AWS account, Docker registry, S3 bucket. You will have to replace the details with your AWS details, but the steps remain similar.
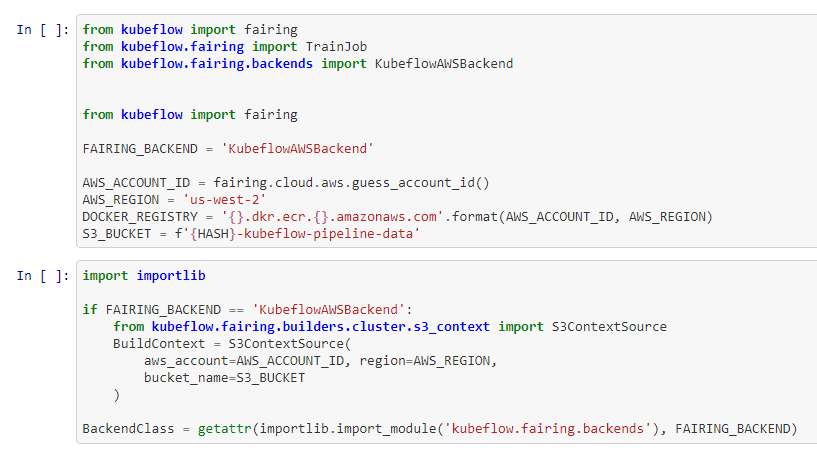
- Training remotely on AWS – You can submit your ML training job on AWS in just two lines by using TrainJob module of Fairing. The HousingServe class, training data, and AWS docker image are passed as arguments.

- Deploy Model on AWS – Similarly, deployment of the ML model on AWS is quite easy with the help of PredictionEndpoint module of Fairing. Make note, this time, you are passing the trained model file in the argument.

- Serving Prediction – The earlier step will generate a prediction endpoint which can be used in the following way for serving prediction. Replace the <endpoint> with the output of the above section.

As shown in the example, a Data Scientist only needs to focus on step 1, the ML model creation and other related data pre-processing tasks. All other steps from 2 to 5 are standard Fairing code which is relatively easy to execute for remote training and deployment on the cloud.
Conclusion
This article gave a gentle introduction to Kubeflow for data scientists and touched upon why Kubeflow is an important machine learning toolkit for data scientists. You also saw various functionalities offered by Kubeflow and finally understood Kubeflow Python SDK, Fairing with the help of an example.
If you like this article, you might also like Building Machine Learning Models to Solve Practical Problems – Simple Talk (red-gate.com)
The post Kubeflow for data scientists introduction appeared first on Simple Talk.
from Simple Talk https://ift.tt/3ou3ZVx
via
No comments:
Post a Comment