What is Unstructured Data?
Structured data is represented by tables, rows, columns, attributes mostly like relational database. Many of us might have spent the better part of our careers working on structured data and it is heavily used for analytical purposes.
Unstructured data is often best described in contrast to structured data. It is an information that does not have a predefined data model and does not fit well into relational tables. It is classified into two types Non – Textual unstructured data and Textual unstructured data.
We going to discuss how to handle Textual unstructured data using DataStage.
What is Textual Unstructured Data?
Textual Unstructured Data is a textual data found in reports, emails, financial records, medical records, spreadsheets etc.
Why can’t we use Sequential file stage to handle Unstructured Data?
Flat flies are commonly used as source/target file and using sequential file stage, we process flat flies. We can use sequential file stage to read the data in excel file, but only if the excel contains data in a single sheet.
We can use Unstructured Data stage to pull data from excel file, when the data is spread across multiple sheets or even when excel contains data in a single sheet
Implementation in ETL (DataStage)
Unstructured Data stage can be used only in parallel job not in server or sequence job. This stage can be found under “File” section in Palette in the Designer. Data can be written or read from this stage
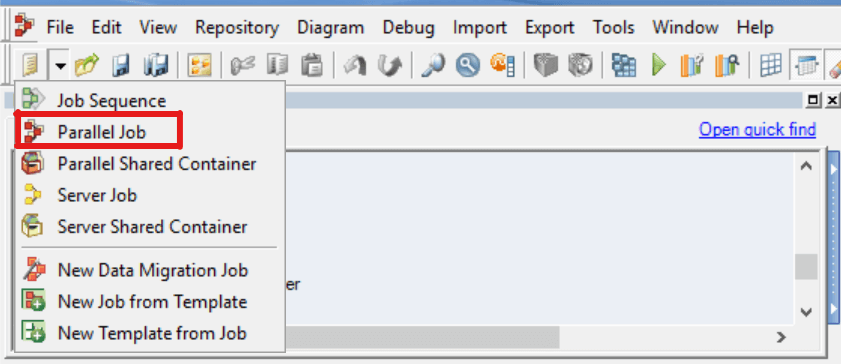
Step 1:
- Select New Parallel Job from Toolbar
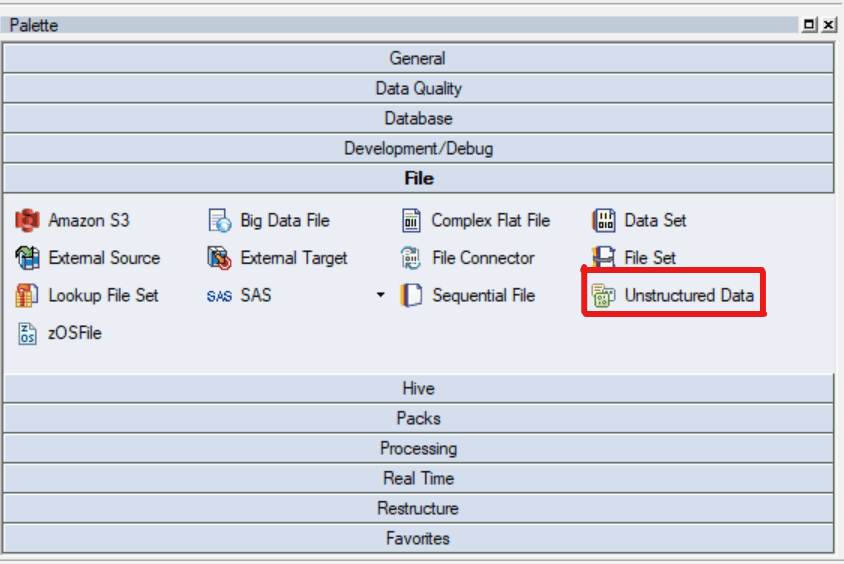
Step 2:
- Select and drag an Unstructured Data stage from the File section of Palette and a target stage to write data and link source and target stages with transformer stage.
Source File: Excel spreadsheet with loan information, “SBA_PPP_MasterList.xlsx”
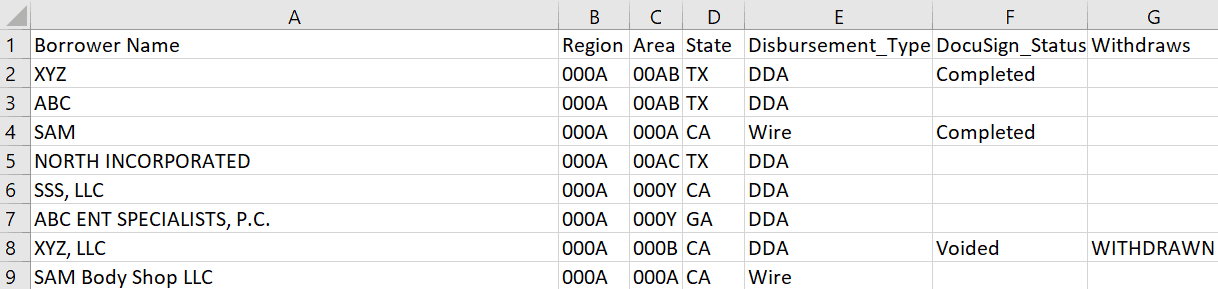
Sheet 1:
Step 3:
- Define properties to extract data. Below is the snapshot of properties tab.
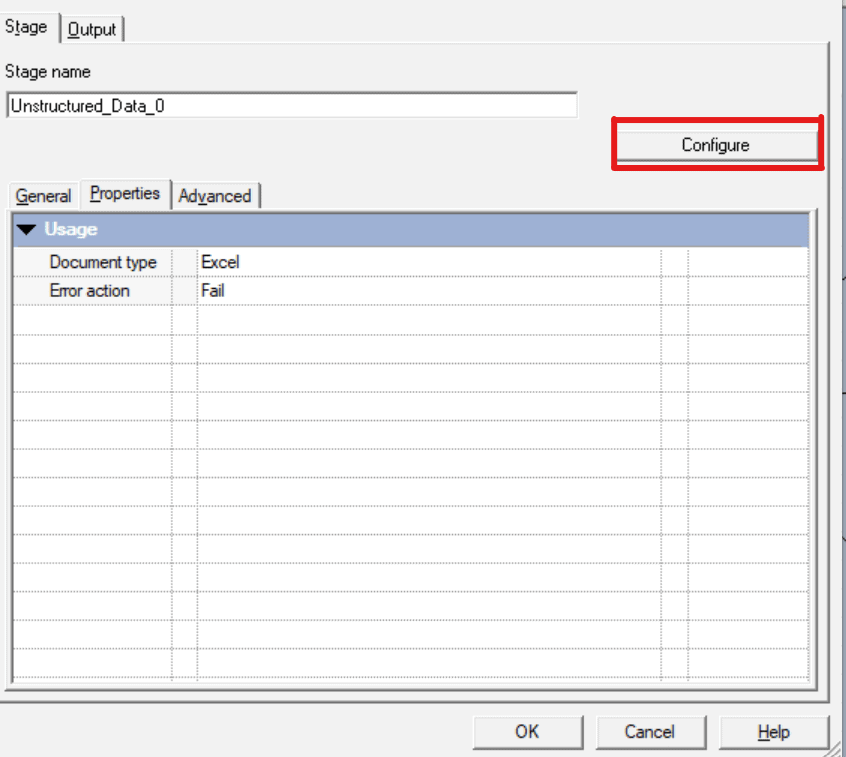
By clicking on the Configure button highlighted in the above snapshot, we will get the properties window of configuration.
Below is the snapshot for configure properties
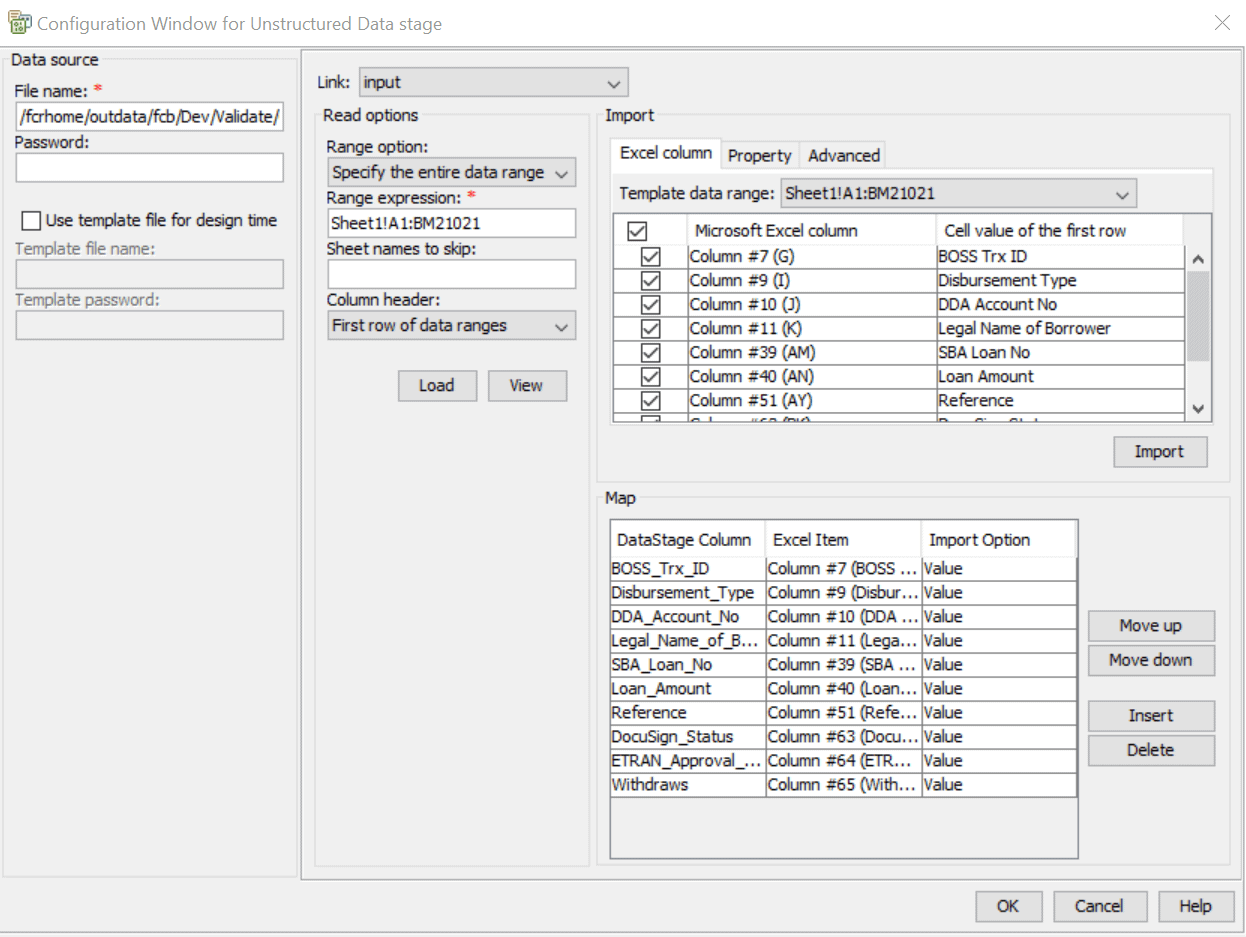
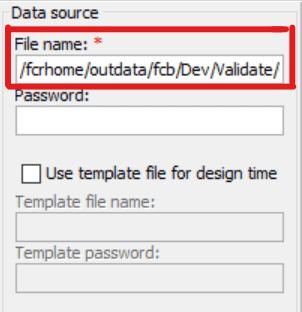
Give file name of the source file along with the path in the File name field.
In the Range expression field from the Read options, give the range of the data in the sheet
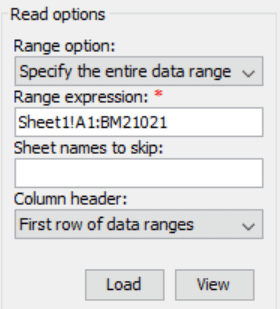
Before selecting Range expression, you need to select an option in Range option. The Range option property of Unstructured Data stage allows you to specify the data range either by selecting the “Specify the start row” option or the “Specify the entire data range” option.
- By selecting the Specify the start row, you need to identify the start row and Data stage identifies the end row of the range.
- By selecting the Specify the entire data range, you must specify the start and end rows of the range to be extracted.
Using Sheet names to skip, we can skip the sheets which are not required.
Once we select the Range option, Range expression, Sheet names to skip and Column header, click on the load button for importing the metadata.
Click on Import to load metadata into Map tab
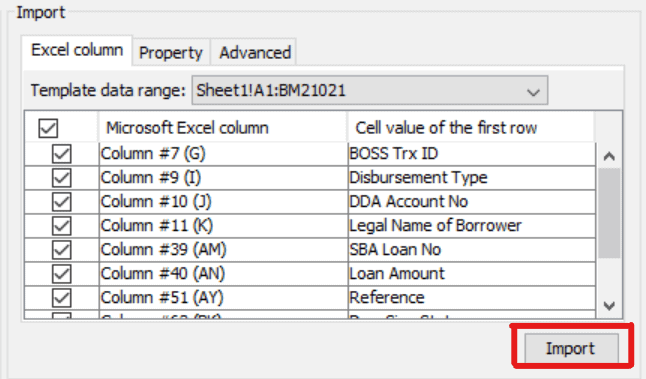
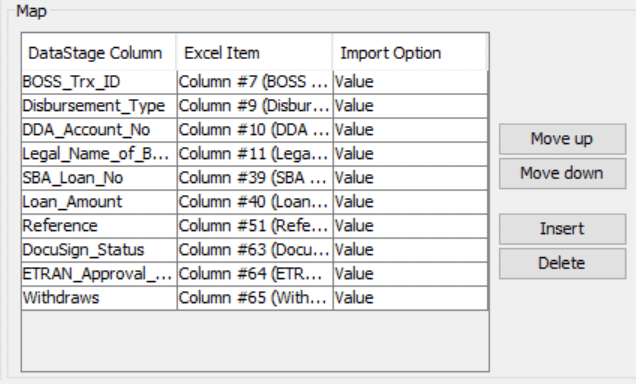
Step 4:
- I have used the Transformer stage connected to the Unstructured Data stage to apply conditions/transformations and to rename/drop columns if needed and mapped to target files.
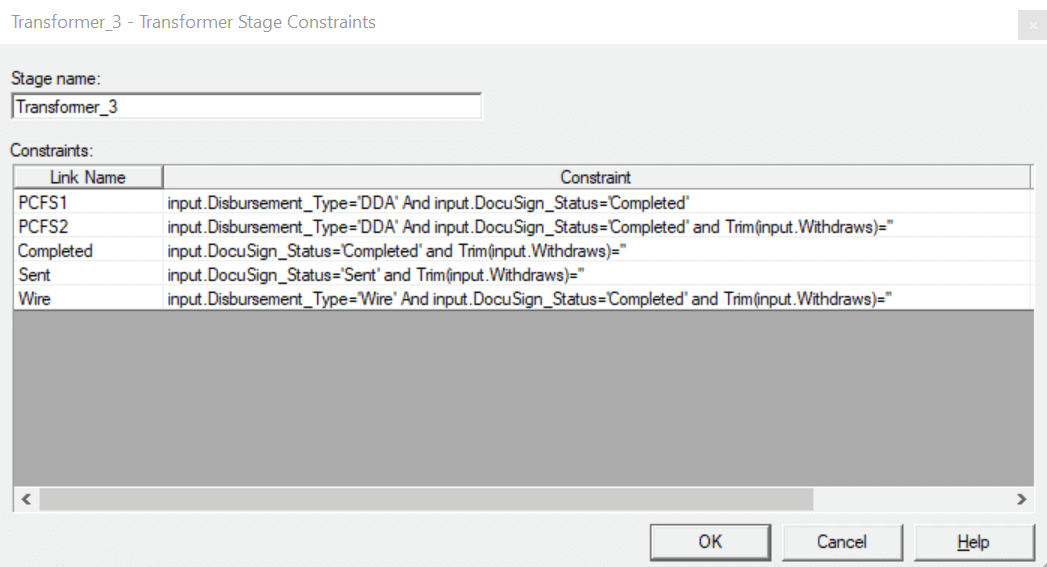
I have filtered the records based on “Disbursement_Type”, “DocuSign_Status” and “Withdraws”. You can find constraints in the above snapshot.
Step 5:
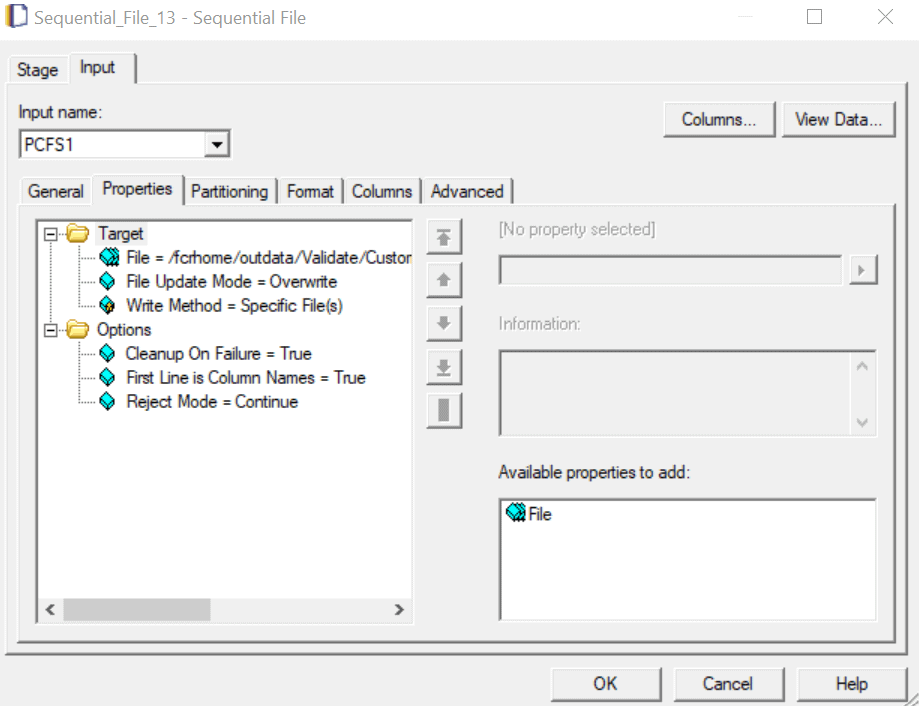
- There are five target systems for this job design. Out of these five, two are Sequential stages and three are Unstructured Data stages.
Job Design:
Here DataStage job has been designed with seven stages.
- Unstructured Data Stage (Source)
- Transformer
- Sequential File Stage (Target)
- Unstructured Data Stage (Target)
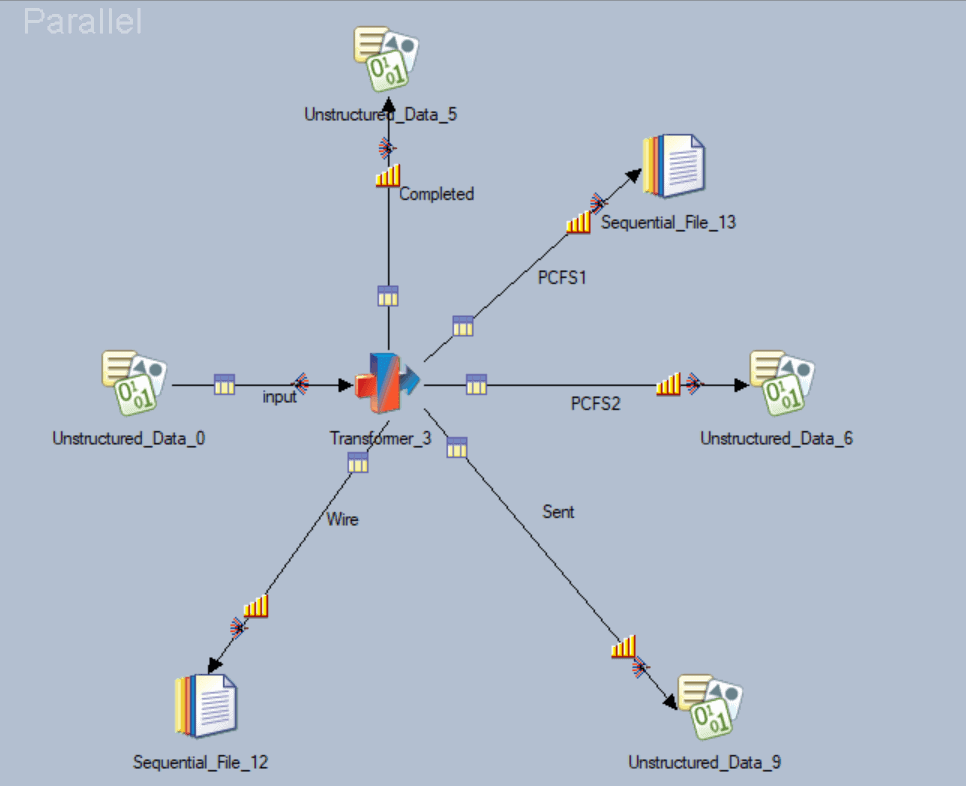
- Load Data into target Sequential File stage
- Load Data into Unstructured Data stage
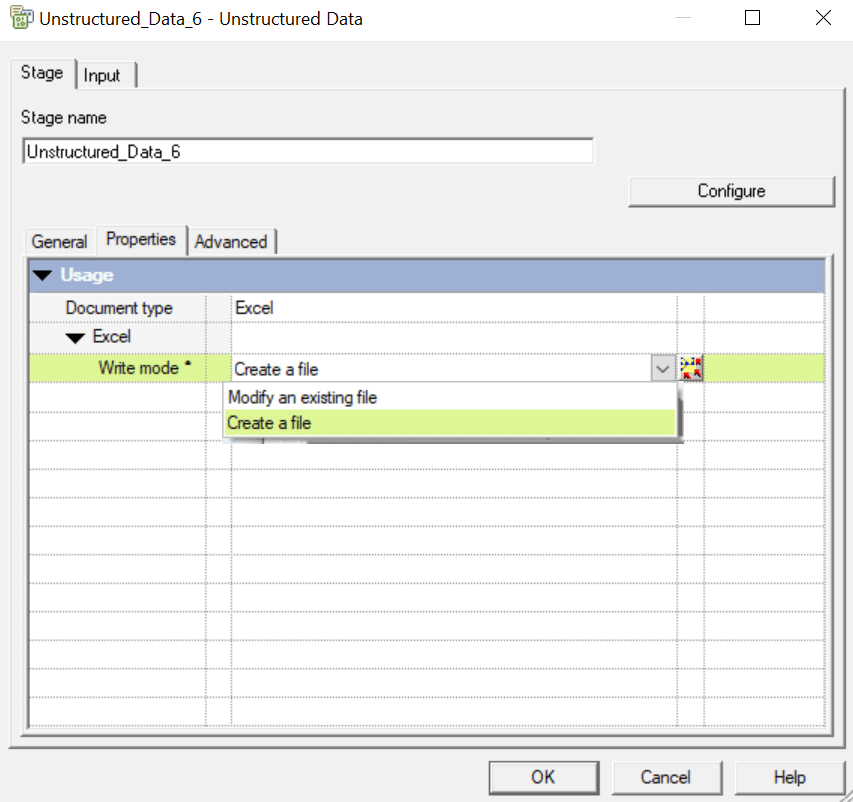
Select an Option from “Modify an existing file” or “Create a file” from Write mode in Properties tab. Then click on “Configure” to select a file name.
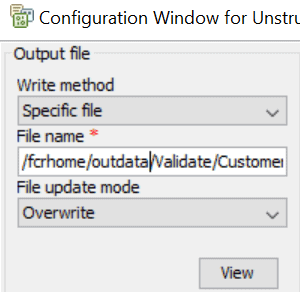
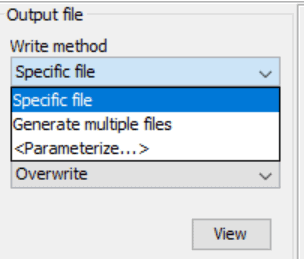
Select either “Specific file” or “Generate multiple files” from Write method and “Overwrite” or “Create (Error if exists) from File update mode.
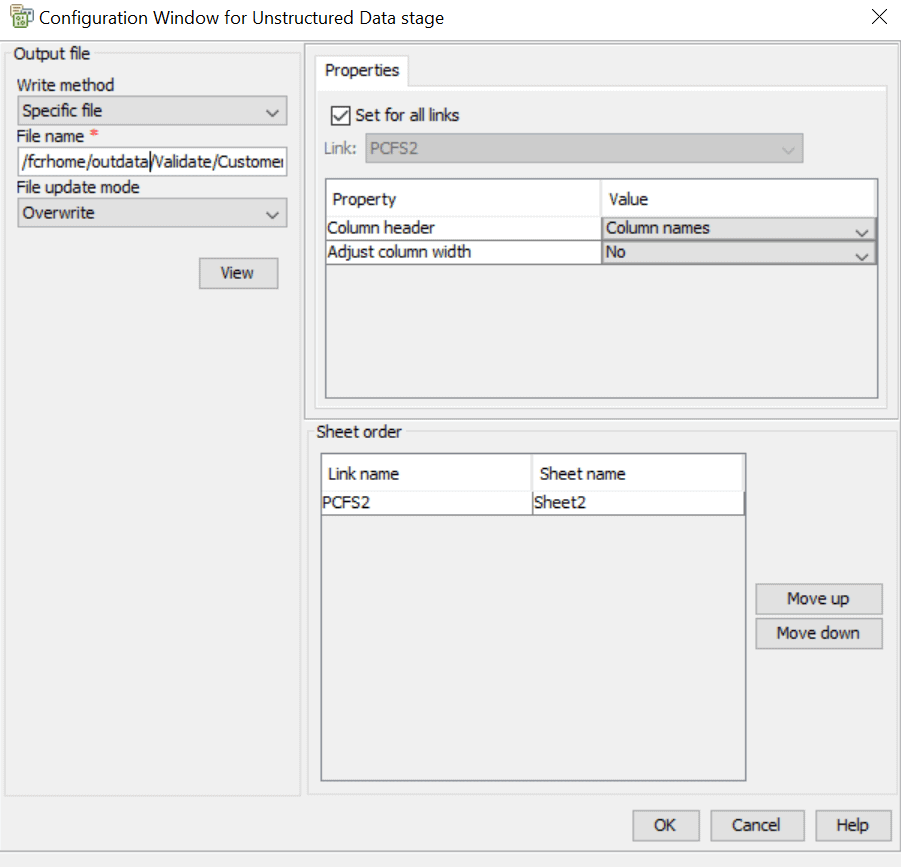
You can set “Yes” or “No” to Adjust column width from Properties tab in Configuration Window and Set the same property for all links. You can also, rename the Sheet name in Sheet order tab
An Unstructured Data stage as a target system, allows multiple input links. This property allows us to write data into multiple sheets in one or more MS Excel spreadsheets.
This process can be widely used to process enterprise data especially in financial domain like Banks etc., to join transactional or accounts data from multiple sheets or to load data into multiple sheets for reporting purposes
The post Handling Textual Unstructured Data using DataStage appeared first on Simple Talk.
from Simple Talk https://ift.tt/39hmUh8
via
No comments:
Post a Comment